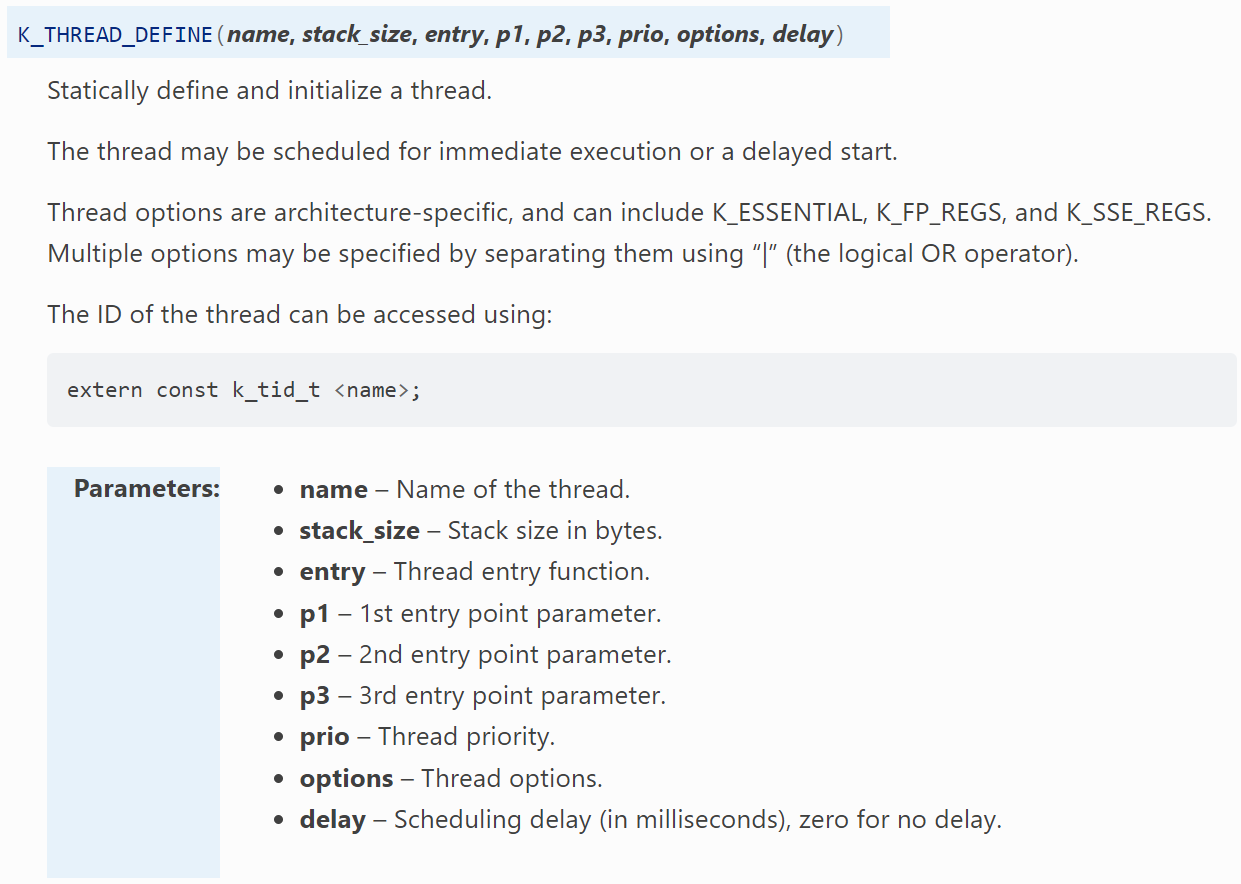
In this exercise, we will learn how to create and initialize two threads and learn how they can affect one another with their priorities. There are two ways to create a thread in Zephyr, the first one is dynamically (at run-time) through k_thread_create() and the other method, which is more frequently used, is statically (at compile time) by using the K_THREAD_DEFINE()macro. This is the macro for defining and initializing a thread and plugging its data structures into the RTOS kernel, it has the API shown below:
Even though the threads are simple in this exercise, we are setting a stack size of 1024. Stack sizes should always be a power of two (512, 1024, 2048, etc.).
Note
In actual application development, you should choose the stack sizes more carefully, to avoid unnecessarily using the stack size. We do not need that here for a simple application.
We are giving the two threads the same priority. In this case, the actual number used isn’t important.
3. The thread entry functions for the two threads (thread0 and thread1) are provided for you, but they contain no code. For now, let’s make them do something very simple which is just print a string in a while-loop.
Add the following printk() statement inside the thread0 and thread1 entry function. Make sure to change the name of the second thread to thread1.
Copy
printk("Hello, I am thread0\n");
C
Since the threads have no dependency on each other and neither yield nor sleep, they will always be in the “Runnable” state competing for the CPU resource.
4. Now that we have defined the necessary parameters, we can define the two threads, thread0 and thread1, using K_THREAD_DEFINE(). Pass the thread’s name to be created, its stack size, thread entry function, optional arguments to pass to the thread up on starting(up to three), the thread’s priority, optional thread options, and finally, an optional scheduling delay.
For the optional arguments passed to the thread, we will pass NULL.
For the optional thread options, which can allow us to configure, for example, if the thread is to be treated as an essential thread K_ESSENTIAL. It instructs the kernel to treat the termination or aborting of the thread as a fatal system error. By default, the thread is not considered to be an essential thread. We will not set an option in this exercise.
For the optional scheduling delay, we will also set it to zero, meaning the thread will be created and put in the ready state right away.
The name can be anything but is used as the thread ID, so name wisely.
5. Build the application and flash it on your development kit. Using a serial terminal you should see the below output:
*** Booting nRF Connect SDK ***Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0Hello, I am thread0
Terminal
Notice that we only see output from thread0, indicating that thread1 never gets to run even though both threads were created with the same parameters and priority. The second thread is being starved, meaning it’s constantly being blocked since thread0 never yields, or waits (sleeps), or does any other event that triggers a rescheduling point.
Let’s see how we can fix this.
Thread yielding
To avoid starving thread1, we will make thread0 voluntarily yield using k_yield().
k_yield() causes the current thread to give away execution (yield) to another thread of the same or higher priority. The thread will be in the “Runnable” state, just pushed to the end of the list of “Runnable” threads. If there are no other threads in that list of the same or higher priority, the threads runs again immediately.
Note
To give lower priority threads a chance to run, the current thread needs to be put to “Non-runnable”. This can be done using k_sleep(), which we will see further on in this exercise.
A thread normally yields when it either has nothing else to do or wants to give other equal or higher priority threads a chance to run. There is usually some logic behind when a thread wants to call k_yield(). To keep this exercise simple, let us make thread0 yield every time it completes the printk() message.
6. Change the entry function of thread0 so it yields after running printk().
Copy
k_yield();
C
7. Build the application and flash it on your development kit. Using a serial terminal you should now see the below output:
*** Booting nRF Connect SDK ***Hello, I am thread0Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1Hello, I am thread1
Terminal
Notice that thread0 is now able to print one message and then yields voluntarily to equal or higher priority threads. Since there is another equal priority thread in the “Runnable” state, this thread is now made active by the scheduler and will get the CPU time. Since thread1 never yields it will run forever once it becomes active, starving thread0.
8. Let’s make thread1 yield as well by adding k_yield() after it prints its message.
Copy
k_yield();
C
9. Build the application and flash it on your development kit. Using a serial terminal you should now see the below output:
*** Booting nRF Connect SDK ***Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1
Terminal
And the events on the CPU look similar to the ones below
Timeline when both threads yield
Since both threads now yield after printing a message, the scheduler comes into play between every thread to evaluate if there are any runnable threads in the queue. Since both threads have equal priority, the scheduler will always choose the other thread as the next running thread, resulting in the two threads alternating each time they’ve run.
The disadvantage of this is that yielding this often and thereby invoking the scheduler also takes up CPU time. The scheduler uses CPU time to do the book-keeping of the kernel resources every time k_yield() is called which in turn costs power. A system with good architecture entails designing your threads so the scheduler uses a minimal amount of CPU time, i.e designing threads that have correct priorities and are reasonably considerate (yielding/sleeping/waiting) to other threads.
Thread sleeping
Since printing is a noncrucial task, it is acceptable for our threads to print less frequently. Therefore, a better option can be for the threads to sleep rather than yield. When sleeping, threads are put in the “Non-runnable” state and do very little processing. This is done by using k_sleep() or some derivative, like k_msleep().
More on this
k_sleep() expect a parameter of type k_timeout_t which can be constructed using macros like K_MSEC(). For simplicity, k_sleep() has simpler-to-use derivatives like k_msleep() and k_usleep() that you can pass the time unit directly. The latter will be used extensively.
10. Let’s try this out by replacing the k_yield() function in both threads with k_msleep(5), i.e a sleep duration of 5 ms. Now the threads should look like below:
Copy
voidthread0(void){while (1) {printk("Hello, I am thread0\n");k_msleep(5); }}voidthread1(void){while (1) {printk("Hello, I am thread1\n");k_msleep(5); }}
C
11. Build the application and flash it on your development kit. Using a serial terminal you should now see the below output:
*** Booting nRF Connect SDK ***Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1Hello, I am thread0Hello, I am thread1
Terminal
Although the output looks identical to when the threads were using k_yield(), there is a significant difference here. The threads are printing less frequently and thereby calling the scheduler less frequently. Take a look at the time sequence graph below and look at the idle period during which the system can switch to low power states.
Timeline when both threads sleep
As you can see, when both threads sleep for a certain amount of time and there are no other ready threads that can be made active by the scheduler, it makes the idle thread (which is one of the system threads) active.
In conclusion:
k_yield() will change the thread state from “Running” to “Runnable”, which means that at the next rescheduling point, the thread that just yielded is still a candidate in the scheduler’s algorithm for making a thread active (“Running”). The overall result is that after the thread yields, there will be at least one item in the runnable thread queue for the scheduler to choose from at the next rescheduling point.
k_sleep() will change the thread state from “Running” to “Non-runnable” until the timeout has passed, and then change it to “Runnable”. This means that the thread will not be candidate in the scheduler’s algorithm until the timeout amount of time has passed. Hence thread sleeping is better choice for adding delays and not for yielding.
The solution for this exercise can be found in the GitHub repository, in l7/l7_e1_sol.
Nordic Developer Academy Privacy Policy
1. IntroductionÂ
In this Privacy Policy you will find information on Nordic Semiconductor ASA (“Nordic Semiconductorâ€) processes your personal data when you use the Nordic Developer Academy.
References to “we†and “us†in this document refers to Nordic Semiconductor.
2. Our processing of personal data when you use the Nordic Developer AcademyÂ
2.1 Nordic Developer AcademyÂ
Nordic Semiconductor processes personal data in order to provide you with the features and functionality of the Nordic Developer Academy. Creating a user account is optional, but required if you want to track you progress and view your completed courses and obtained certificates. If you choose to create a user account, we will process the following categories of personal data:
Email
Name
Password (encrypted)
Course progression (e.g. which course you have completely or partly completed)
Certificate information, which consists of name of completed course and the validity of the certificate
Course results
During your use of the Nordic Developer Academy, you may also be asked if you want to provide feedback. If you choose to respond to any such surveys, we will also process the personal data in your responses in that survey.
The legal basis for this processing is GDPR article 6 (1) b. The processing is necessary for Nordic Semiconductor to provide the Nordic Developer Academy under the Terms of Service.
2.2 AnalyticsÂ
If you consent to analytics, Nordic Semiconductor will use Google Analytics to obtain statistics about how the Nordic Developer Academy is used. This includes collecting information on for example what pages are viewed, the duration of the visit, the way in which the pages are maneuvered, what links are clicked, technical information about your equipment. The information is used to learn how Nordic Developer Academy is used and how the user experience can be further developed.
2.2 NewsletterÂ
You can consent to receive newsletters from Nordic from within the Nordic Developer Academy. How your personal data is processed when you sign up for our newsletters is described in the Nordic Semiconductor Privacy Policy.
3. Retention periodÂ
We will store your personal data for as long you use the Nordic Developer Academy. If our systems register that you have not used your account for 36 months, your account will be deleted.
4. Additional informationÂ
Additional information on how we process personal data can be found in the Nordic Semiconductor Privacy Policy and Cookie Policy.
â€â€Â
Nordic Developer Academy Terms of Service
1. Introduction
â€These terms and conditions (“Terms of Useâ€) apply to the use of the Nordic Developer Academy, provided by Nordic Semiconductor ASA, org. nr. 966 011 726, a public limited liability company registered in Norway (“Nordic Semiconductorâ€). â€
Nordic Developer Academy allows the user to take technical courses related to Nordic Semiconductor products, software and services, and obtain a certificate certifying completion of these courses. By completing the registration process for the Nordic Developer Academy, you are agreeing to be bound by these Terms of Use.
These Terms of Use are applicable as long as you have a user account giving you access to Nordic Developer Academy.â€
â€2. Access to and use of Nordic Developer Academy
â€â€Upon acceptance of these Terms of Use you are granted a non-exclusive right of access to, and use of Nordic Developer Academy, as it is provided to you at any time. Nordic Semiconductor provides Nordic Developer Academy to you free of charge, subject to the provisions of these Terms of Use and the Nordic Developer Academy Privacy Policy.
To access select features of Nordic Developer Academy, you need to create a user account. You are solely responsible for the security associated with your user account, including always keeping your login details safe.
You will able to receive an electronic certificate from Nordic Developer Academy upon completion of courses. By issuing you such a certificate, Nordic Semiconductor certifies that you have completed the applicable course, but does not provide any further warrants or endorsements for any particular skills or professional qualifications.
Nordic Semiconductor will continuously develop Nordic Developer Academy with new features and functionality, but reserves the right to remove or alter any existing functions without notice.
â€3. Acceptable use
You undertake that you will use Nordic Developer Academy in accordance with applicable law and regulations, and in accordance with these Terms of Use.†You must not modify, adapt, or hack Nordic Developer Academy or modify another website so as to falsely imply that it is associated with Nordic Developer Academy, Nordic Semiconductor, or any other Nordic Semiconductor product, software or service.
You agree not to reproduce, duplicate, copy, sell, resell or in any other way exploit any portion of Nordic Developer Academy, use of Nordic Developer Academy, or access to Nordic Developer Academy without the express written permission by Nordic Semiconductor. You must not upload, post, host, or transmit unsolicited email, SMS, or \”spam\” messages.
You are responsible for ensuring that the information you post and the content you share does not;
contain false, misleading or otherwise erroneous information
infringe someone else’s copyrights or other intellectual property rights
contain sensitive personal data or
contain information that might be received as offensive or insulting.
Such information may be removed without prior notice.
â€Nordic Semiconductor reserves the right to at any time determine whether a use of Nordic Developer Academy is in violation of its requirements for acceptable use.
Violation of the at any time applicable requirements for acceptable use may result in termination of your account. We will take reasonable steps to notify you and state the reason for termination in such cases.
â€4. Routines for planned maintenance
â€Certain types of maintenance may imply a stop or reduction in availability of Nordic Developer Academy. Nordic Semiconductor does not warrant any level of service availability but will provide its best effort to limit the impact of any planned maintenance on the availability of Nordic Developer Academy.
5. Intellectual property rights
â€Nordic Semiconductor retains all rights to all elements of Nordic Developer Academy. This includes, but is not limited to, the concept, design, trademarks, know-how, trade secrets, copyrights and all other intellectual property rights.
Nordic Semiconductor receives all rights to all content uploaded or created in Nordic Developer Academy. You do not receive any license or usage rights to Nordic Developer Academy beyond what is explicitly stated in this Agreement.
â€6. Liability and damages
â€Nothing within these Terms of Use is intended to limit your statutory data privacy rights as a data subject, as described in the Nordic Developer Academy Privacy Policy. â€You acknowledge that errors might occur from time to time and waive any right to claim for compensation as a result of errors in Nordic Developer Academy. When an error occurs, you shall notify Nordic Semiconductor of the error and provide a description of the error situation.
You agree to indemnify Nordic Semiconductor for any loss, including indirect loss, arising out of or in connection with your use of Nordic Developer Academy or violations of these Terms of Use. â€Nordic Semiconductor shall not be held liable for, and does not warrant that (i) Nordic Developer Academy will meet your specific requirements, (ii) Nordic Developer Academy will be uninterrupted, timely, secure, or error-free, (iii) the results that may be obtained from the use of Nordic Developer Academy will be accurate or reliable, (iv) the quality of any products, services, information, or other material purchased or obtained by you through Nordic Developer Academy will meet your expectations, or that (v) any errors in Nordic Developer Academy will be corrected.
You accept that this is a service provided to you without any payment and hence you accept that Nordic Semiconductor will not be held responsible, or liable, for any breaches of these Terms of Use or any loss connected to your use of Nordic Developer Academy. Unless otherwise follows from mandatory law, Nordic Semiconductor will not accept any such responsibility or liability.
â€7. Change of terms
â€Nordic Semiconductor may update and change the Terms of Use from time to time. Nordic Semiconductor will seek to notify you about significant changes before such changes come into force and give you a possibility to evaluate the effects of proposed changes. Continued use of Nordic Developer Academy after any such changes shall constitute your acceptance of such changes. You can review the current version of the Terms of Use at any time at https://academy.nordicsemi.com/terms-of-service/
â€8. Transfer of rights
â€Nordic Semiconductor is entitled to transfer its rights and obligation pursuant to these Terms of Use to a third party as part of a merger or acquisition process, or as a result of other organizational changes.
â€9. Third Party Services
â€â€To the extent Nordic Developer Academy facilitates access to services provided by a third party, you agree to comply with the terms governing such third party services. Nordic Semiconductor shall not be held liable for any errors, omissions, inaccuracies, etc. related to such third party services.
â€10. Dispute resolution
â€â€The Terms of Use and any other legally binding agreement between yourself and Nordic Semiconductor shall be subject to Norwegian law and Norwegian courts’ exclusive jurisdiction.
Switch language?
Progress is tracked separately for each language. Switching will continue from your progress in that language or start fresh if you haven't begun.
Your current progress is saved, and you can switch back anytime.
•This release includes Long-Term Support (LTS) for five years.
•Patch (minor) releases will address security vulnerabilities and critical bug fixes.
•API stability is guaranteed; breaking changes are only introduced when required by a security fix.
•Notifications for critical bug fixes and security updates via the myNordic notification system (mynordic.nordicsemi.com)
General updates
•Support for nRF54LS05 DK (Available through the early access sampling program) •Support for the nRF54LM20B with Axon NPU for Edge AI applications
Bluetooth LE updates
•Quality of Service module is now production-ready. •New experimental features for RF testing (Direct Test Mode) and low-latency packet handling (LE Flushable ACL).
MCUboot & Partition Manager
•Single-Slot DFU and RAM Load mode are both promoted to fully supported •Partition Manager is officially deprecated in favor of Zephyr's devicetree-based partitioning.
General updates
•Added comprehensive support for the nRF54L Series. •Bug fixes and improvements. •Hardware model v1, which was deprecated in nRF Connect SDK 2.7.0, has now been removed. •Multi-image builds functionality (parent-child images), which was deprecated in nRF Connect SDK v2.7.0 has now been removed.
Bluetooth LE updates
•Added support for Bluetooth Core version 6.2. •Added support for Bluetooth LE Shorter Connection Intervals. •Added support for Bluetooth LE Channel Sounding.
Bootloader updates
•Support for MCUboot image compression. •Single slot DFU support for the nRF54L Series. •Encrypted DFU support using ECIES on the nRF54L15, nRF54LM20, and nRF54LV10 SoCs.